
一、序言:从零开始的大模型行业洞察
自2024年末幻方公司发布并开源DeepSeek-V3以来,中国乃至全球的大模型市场迎来了一股强劲的新生力量。在DeepSeek问世之前,市场的焦点主要集中在OpenAI的GPT系列,其发展路径依赖于大规模算力基础设施(如显卡集群)、海量数据训练以及超高参数量的模型构建(通常达到千亿甚至万亿级别,故称为“大模型”)。
这种发展模式存在显著问题。首先,依赖巨额投入打造的大模型使用成本极高。以GPT-4为例,每百万字符的交互成本在500-1000元,这涵盖了显卡采购与折旧、训练过程中的电力消耗以及企业研发投入和盈利目标等多重因素。其次,尽管中国在人工智能人才储备、能源资源、通信基础设施和计算机新基建方面具备优势,但由于美国对显卡出口的制裁,中国的算力资源长期受限,算力成本居高不下,导致大模型的研发效率和商业化进程难以与美国公平竞争,长期处于落后状态。
为突破困局,DeepSeek以其"高效率、低成本、国产适配、生态开源"的战略定位,通过参数效率优化(知识蒸馏、稀疏化架构等)与学习算法深度改进,在保持万亿参数规模与先进性能的同时,显著降低了训练开发成本,并实现国产芯片适配;同时,将终端用户使用成本降至极低水平(百万字符约10元),形成“突破性技术+开源生态+商业化落地”的三轮驱动,一方面通过社区协作加速算法迭代和垂直场景落地,另一方面以低门槛使用成本打破传统大模型的资源垄断格局。
本次研究报告采用计划通过四期进行发布:分别阐述大模型发展的软件理论架构与硬件支撑体系,以及试图重点解构全球大模型市场竞争格局,包括以美国为主导的产业底层秩序、中国在该领域的突围路径,以及DeepSeek横空出世引发的行业范式革命。
在论证逻辑上,本研究将以自然语言处理(NLP)这一AI核心领域为切入点,通过三重维度展开深入分析:首先纵向梳理NLP技术演进脉络与产业化应用场景,解构支撑大模型爆发的算力基础;其次横向对比OpenAI等标杆案例,透视中美两国在大模型赛道的发展差异与竞争态势;最后聚焦DeepSeek的破局性贡献——不仅体现在幻方团队创新的模型架构设计,更开创性地构建了开源生态体系,其革命性的成本优势(百万字符交互成本低至10元)正在重塑行业标准。基于上述分析,本研究将进一步展望大模型技术演进对通用人工智能(AGI)发展路径的深远影响。
二、大模型的技术演进综述
(1)技术演进与技术范式脉络
自然语言处理(Natural Language Processing, NLP)作为通用人工智能(Artificial General Intelligence, AGI)研发的重要分支之一,一直是行业内的研发关键点。而自2023年以来,以ChatGPT为代表的LLM大语言模型的商业化应用爆发,快速地拉近了普通消费者与AI的距离,AI仿佛是一夜之间便完成了从荧幕形象(如流浪地球系列中的强人工智能MOSS小苔藓)到实际生活的渗透。
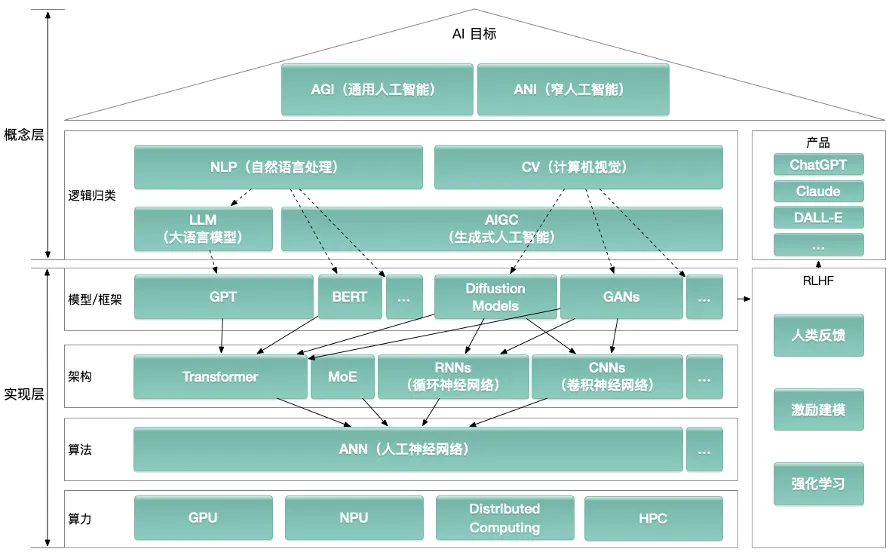
AI全景知识图谱,来源,知乎-范乘瑞
那么到底什么是AGI,什么是自然语言处理,什么又是大模型,更加具体到ChatGPT和最近爆火的Deepseek。为什么Deepseek仿佛一夜之间春风来,变成大街小巷里都能见到的概念?本文试图通过NLP作为技术切入点,对大模型行业进行整体介绍。
(2)自然语言处理的前世今生:
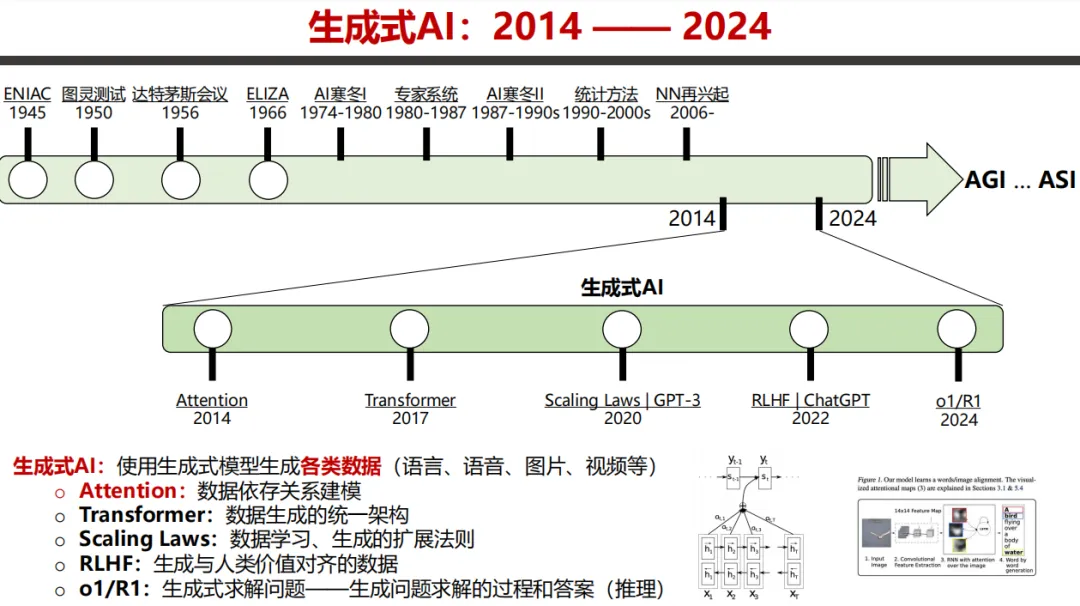
图片截取自天津大学自然语言处理实验室《深度解读DeepSeek:原理与效应》
自然语言处理(Natural Language Processing, NLP)技术最早可以追溯到1954年的IBM 701机器,该机器的设计理念为通过机器编程,实现字典式的俄英文本替换翻译,但由于语言底层逻辑的错位,以及同义词多义词等因素,机器翻译的准确率长期维持在60%左右的语言准确率,更不用谈翻译的信达雅水平。

图片截取自天津大学自然语言处理实验室《深度解读DeepSeek:原理与效应》
到了 1990 年代,IBM 采用SMT统计方法加强了机器翻译的准确率,由点对点的词语词库对照翻译,转为概率预测词库翻译。机器编程通过分析数百万句对话,通过数学模型使计算机获得了根据上下文猜概率的能力。比如,统计发现 “bank” 后面接“river”时,将其译为 “河岸” 的概率约为70%~80%。但这种“概率游戏”在处理复杂逻辑和长难句时却力不从心。比如遇到“Time flies like an arrow”这样的句子,仍会出现误译,最终输出的结果可能是直接按字面翻译成“时间苍蝇喜欢箭”。
一直到2013年Word2Vec 技术的问世,计算机才首次具备理解词语语义的能力。通过向量空间计算,计算机能够得出 “国王 - 男人 + 女人 = 女王” 这样的结论。而2017 年出现的 Transformer 架构,更是让 AI 学会了 “联系上下文”的能力。它在阅读整段话后,如同人类阅读时会脑补场景一样,能够判断 “苹果” 指的是科技公司还是水果,自此,机器翻译的准确率终于突破了 90%。
当前占据技术应用前沿的ChatGPT、Deepseek等应用,其理论根基始终锚定于Transformer架构——这一革命性框架源自2017年里程碑论文《Attention Is All You Need》。
该架构引发的行业革命体现在两大维度:首次赋予机器在文章长度对自然语言进行语义解构与上下文建模的能力(语义认知维度),继而催生出自动化文本处理、知识推理等实用化技能体系(工程实现维度)。目前主流的机器技能图谱如下,我们也将就目前行业主流案例做出简介:
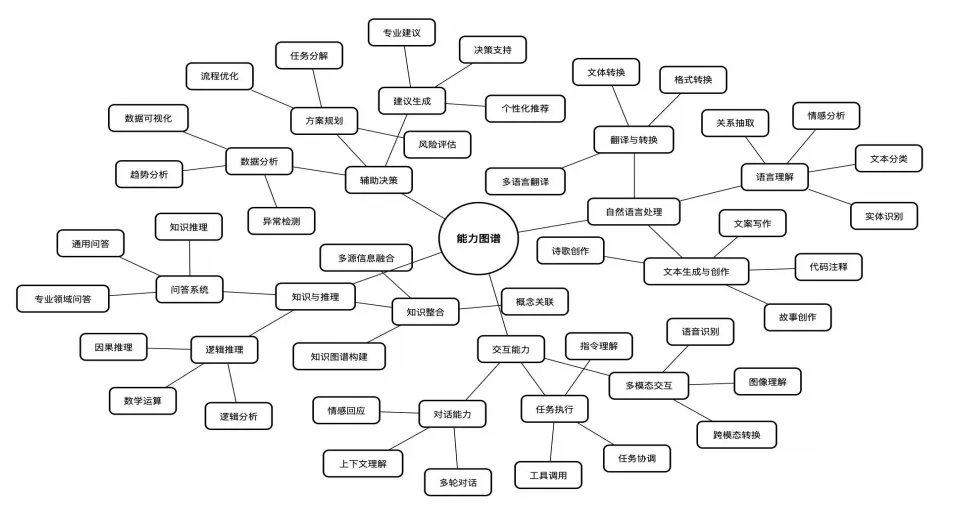
图片截取自清华大学新闻与传播学院《DeepSeek:从入门到精通》
1、智能写作:美联社利用 AI 撰写财报,数秒钟就能生成一篇200-300字的报道,而且错误率比人工更低。
2、机器翻译:谷歌翻译支持 133 种语言,即便是梵文诗歌,也能被译成押韵的中文。
3、医疗病历分析:在某大型医院,通过部署一个基于NLP的医疗记录自动分类与编码系统,用于自动识别和分类病历中的疾病名称,并将其映射到ICD-10编码,经过一段时间的运行,系统的准确率达到了95%以上,大大提高了工作效率。

4、金融舆情监测:彭博社的系统能够实时分析财报电话会,通过数秒钟的量化指标分析,就能识别出 “业绩暴雷” 信号。
5、司法文书处理:上海法院的“数助办案”系统集成了案件要素分析、争议归纳、证据指引、裁判文书生成等智能化功能。AI助理通过学习类案办案要件指南和适法文件知识库,能够快速输出裁判文书的核心内容,例如一键生成赔偿金额计算(如“道交计算器”)。此外,系统还支持文书自动纠错、法律条文附录、排版打印等,已累计辅助生成近15.8万篇次裁判文书。
虽然目前NLP已经完成了从0-60-90的跨越式发展,但从90-100的最后一段路实际上也并非一帆风顺。目前来看,主要存在的问题包括三个方面:
1、词汇歧义:一词千面的困局
以 “小米发布了新手机” 这句话为例,AI 需要判断这里的 “小米” 指的是科技品牌,而不是粮食。“这个方案很水” 这句话,要区分 “水” 是指 “含水量高” 还是 “质量差”。而在语音交互中,中文的同音词问题更为严重,比如“攻击” 与 “公鸡” 甚至会引发致命误解。
2、文化语境:跨越巴别塔的难题
由于西方的 AI 曾经就西方文学作品进行了大量学习,在概率中,将 “龙” 翻译为邪恶生物的指向性很强。但是在东方文化中,龙往往是祥瑞的象征,如在电影《哪吒》中,错误的文化背景,会让翻译的逻辑走向产生严重的分歧。而日语、德语等语系独特的敬语系统也常常让机器翻译失灵,比如需要针对 “です / ます” 等敬体用法进行特别训练。
3、常识推理:AI 的致命短板
由于整体系统的语义理解是通过概率预测来实现的,在传统的非推理系统中,虽然计算机获得了计算 “1 小时 = 60 分钟”的概率结论,但却难以回答类似“煮鸡蛋需要 10 分钟还是20分钟”的常识问题,因为少有训练文本会明确指向煮鸡蛋和时间的关联概率。对于更复杂的 “外面现在是晴天,但好像要阴天了,小明为什么带伞” 这类因果推理问题,错误率仍高达20%以上。
由于上述弊端,用户在与传统Transformer算法形成模型的交互中,可以清晰感受到模型的机械性和笨拙性(也即无法通过最初级的图灵测试)。直到2020年,以OpenAI提出的基于Scaling Laws的GPT3模型后,Transformer模型在应用中面临的问题才终于有了解决方案,即——通过算力、数据和参数的指数堆叠,形成千亿级别的大参数模型(大模型)。
但在这个过程中,引人深思的是:大模型似乎忽然变得聪明了(如GPT3/4系列产品的强文本处理能力),但却没有一个明确的理论可以指出它变聪明的原因。这是一个典型的量变(参数量)诱发质变(语义理解能力)的案例,不同的是,由于缺乏具体的理论指导,质变的过程完全发生在了参数训练的黑箱之中。
在下一期内容中,我们将从AGI与NLP领域出发,进一步聚焦大模型本身。我们会试图解析:大模型的定义标准、算法特征、2020至2025年的技术演进路径,以及支撑大模型实现的硬件基础。